
앞선 아티클에서 우리는 관계형 데이터베이스의 전반적인 용어의 개념과, 이를 바탕으로 합집합 개념인 UNION에 대해서 살펴보았습니다.
Chapter 3. 집합 연산자와 서브쿼리 - (2) UNION과 합집합 1
우리는 앞서서 아주 간단하고 심플한 방식으로 '관계형 데이터베이스'에서의 용어 개념에 대해서 알아보았습니다. 100% 정확한 내용이라고 볼 수도 없고, 실무적인 내용은 아니지만 어설프게 사
nozeroslope.tistory.com
이제 본격적으로 UNION의 사용에 대해서 살펴보겠습니다.
select COLUMN_1_1, COLUMN_1_2
from table_name_1
union
select COLUMN_2_1, COLUMN_2_2
from table_name_2;
위 예제에서 두 개의 SELECT ~ FROM ~ 문을 UNION 명령어를 통해서 통합하고 있습니다. 이때 중요한 것은, 두 개의 SELECT문이 각각 동일한 개수의 칼럼을 가져야 합니다. 위의 경우 둘 다 칼럼의 개수가 두 개죠. 그리고, 이렇게 선언된 칼럼의 경우 각각 순서대로 데이터 타입이 호환되어야 UNION을 수행할 수 있습니다.
그리고 사소하지만 중요한 특성, 여기서 중복되는 데이터 값은 합집합의 특성에 따라 자동으로 제외됩니다.
예제를 실행해보기 위한 샘플 테이블을 직접 만들어보겠습니다. 비슷한 열 구성과 데이터 값을 갖고 있어야 하겠죠?
create table sales2023_1
(
name varchar(50),
amount numeric(15, 2)
);
insert into sales2023_1
values
('Swings', 150000.25),
('Nochang', 132000.75),
('DAMINI', 100000)
;
create table sales2023_2
(
name varchar(50),
amount numeric(15, 2)
);
insert into sales2023_2
values
('Swings', 120000.25),
('Nochang', 142000.75),
('DAMINI', 100000)
;
select *
from sales2023_1;
select *
from sales2023_2;
위와 같이 예제 테이블을 생성하고 조회를 해보면, 다음과 같이 테이블이 생성 되었음을 확인할 수 있습니다.


이제부터 여러가지 케이스의 UNION 쿼리 동작 결과를 살펴보도록 하겠습니다. 우선 전체를 UNION으로 합쳐보도록 하겠습니다.
select *
from sales2023_1
union
select *
from sales2023_2;

위와 같이 두 개의 테이블 전체를 UNION으로 결합하였습니다. 이때, 한 가지 특이한 것은 행 값 하나가 사라졌다는 것입니다. 바로 ('DAMINI', '100000')이죠. 이는 두 개의 테이블에 모두 완전히 똑같은 값으로 존재하고 있었기 때문에 중복 제거가 발생한 것입니다. NAME이 같더라도 AMOUNT가 다른 행의 경우에는 다른 값으로 취급되어 자신의 형태를 유지하고 있습니다.
자, 이번에는 ' * '를 사용하지 않고 특정 열에 대해서만 UNION을 실행해 보도록 하겠습니다.
select name
from sales2023_1
union
select name
from sales2023_2;

이 경우에는 NAME 열의 데이터만을 합집합으로 가져오게 됩니다. 이 때, 이름만으로 판단하니 중복되는 이름들은 모두 제외되어서 세 개의 값만 남게 됩니다.
비슷한 방식으로 AMOUNT만 UNION을 진행해 보겠습니다.
select amount
from sales2023_1
union
select amount
from sales2023_2;
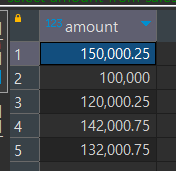
AMOUNT 값 중에서 값이 완전히 동일한 100,000 하나가 제외되었습니다.
○ UNION에서 ORDER BY 사용하기
참고로 위의 데이터 정렬은 임의로 이루어져 있습니다. 그럴 때 우리는 원하는 기준으로 데이터를 정렬하기 위해서 ORDER BY를 사용하게 되죠. 다만, 여기서 두 개 이상의 테이블을 UNION으로 사용할 때는 특별한 사용 조건이 있습니다. 일단 아래의 두 가지 사용 원칙을 기억합시다.
1. ORDER BY는 맨 마지막 SELECT 구문에서만 작성한다.
2. 정렬 기준 칼럼 명은 각 테이블에서 동일한 이름이거나, 혹은 새로 생성한 별명으로 지정한다.
1번 원칙의 경우 맨 마지막 SELECT 문에 작성만 하면 되는 것이니 별로 어려울 것이 없습니다. 그런데 2번 원칙은 조금 헷갈립니다. 예제에서는 다루지 않았지만, 두 개의 테이블에서 같은 순서의 열이 이름이 다른 경우가 존재할 수 있습니다. 예를 들어 SALES2023_1에선 NAME이라는 칼럼이 SALES2023_2에서는 ID라는 칼럼 이름일 경우가 있을 수 있겠죠?(물론 데이터 타입은 동일해서 UNION에 지장 없을 경우)
이때 ORDER BY로 NAME이나 ID를 쓸 수 없기 때문에, 이런 경우에는 AS를 사용해 하나의 별명으로 통일하고, 이를 정렬해야 합니다.
ORDER BY의 사용 예를 살펴보고 이번 아티클을 마무리하겠습니다.
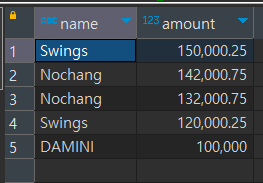
select *
from sales2023_1
union
select *
from sales2023_2
order by amount desc;
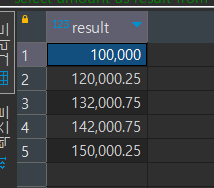
select amount as result
from sales2023_1
union
select amount as result
from sales2023_2
order by result asc;
'Data Literacy > SQL' 카테고리의 다른 글
| Chapter 3. 집합 연산자와 서브쿼리 - (2) UNION과 합집합 3 (0) | 2023.09.16 |
|---|---|
| Chapter 3. 집합 연산자와 서브쿼리 - (2) UNION과 합집합 1 (1) | 2023.08.30 |
| Chapter 3. 집합 연산자와 서브쿼리 - (1) 관계형 데이터베이스의 정의 (0) | 2023.08.24 |
| Chapter 2. JOIN을 이용한 데이터 조합 - (8) 그룹화 : GROUP BY & HAVING 5 [예제] (0) | 2023.08.10 |
| Chapter 2. JOIN을 이용한 데이터 조합 - (8) 그룹화 : GROUP BY & HAVING 4 (0) | 2023.08.02 |



