
이번 아티클에서는 본격적으로 GROUP BY에 대해서 살펴보도록 하겠습니다. 여기서 설명하기 위한 샘플 테이블을 아래 예시와 같이 생성해 보도록 하겠습니다.
create table sample00
(
no int primary key,
name varchar (255),
quantity int
);
insert into sample00(
no,
name,
quantity
)
values
(1, 'A', 1),
(2, 'A', 2),
(3, 'B', 10),
(4, 'C', 3),
(5, null, null);
select *
from sample00;
위 쿼리를 통해서 아래와 같은 테이블이 생성되는 것을 확인할 수 있습니다. 이제 이 테이블을 기준으로 GROUP BY에 대해서 설명을 진행해 보겠습니다.
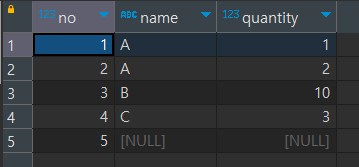
우선 여기서 name 열을 기준으로 GROUP BY 구문을 사용해서 어떤 결과가 나오는지 살펴보겠습니다.
select name
from sample00
group by name;

위의 결과를 보면, SELECT DISTINCT를 사용했을 때와 유사한 결과가 나옵니다. A가 두 개 있었지만 중복이 제거되어 A, B, C, NULL이 각각 대표 그룹명처럼 취급되어 출력되었습니다. 즉, 여기서 지정된 열(NAME)의 값이 같은 행들은 하나의 그룹으로 묶여버리는 것입니다.
다만 GROUP BY를 이런 형식으로만 사용한다면 큰 의미가 없을 것입니다. 이렇게 그룹화된 각각의 그룹은 하나의 집합으로서 집계함수 사용 시 인자 값으로 넘겨지기 때문이지요.
그럼 실제로 NAME열을 기준으로 GROUP BY를 사용할 때, 집계 함수를 함께 사용하는 형태에 대해서 살펴보겠습니다. 단순해 보이지만 꽤 중요한 부분이니 잘 기억해야 할 부분입니다.
select name,
count(name),
sum(quantity)
from sample00
group by name;
위의 예시처럼 GROUP BY를 NAME 기준으로 지정했습니다. 다만, SELECT 항목에서 COUNT(NAME)과 SUM(QUANTITY)를 추가했습니다. 지금 이 쿼리는 결과적으로 [NAME을 기준으로 그룹을 만들고 > 그 NAME 그룹의 개수를 카운트하고 / QUANTITY 열의 합계를 구하라]는 명령을 내린 것입니다.

- A라는 NAME 그룹에 해당하는 행은 2개입니다. 그러므로 2를 리턴합니다.
- A라는 NAME 그룹에 해당하는 2개의 행의 QUANTITY 열 값은 각각 1, 2입니다. 이 값을 합한 값인 3을 리턴합니다.
대략 사용법에 감이 오셨나요? 일단 다음 개념을 다시 한번 되짚어 봅시다.
* 특정 열을 GROUP BY로 정렬하면, DISTINCT를 사용했을 때와 비슷하게 그룹이 생성된다.
* 해당 그룹에 포함되는 열 값들을 기준으로 집계함수 등을 사용해 결과를 리턴한다.
> 이 때 집계되는 값은 해당 그룹에 포함되는 열들의 데이터를 기준으로 집계된다.
여기까지 이해되었다면, 다음 아티클에서 GROUP BY의 조건문인 HAVING에 대해서도 더 살펴보겠습니다.
'Data Literacy > SQL' 카테고리의 다른 글
| Chapter 2. JOIN을 이용한 데이터 조합 - (8) 그룹화 : GROUP BY & HAVING 3 (0) | 2023.07.28 |
|---|---|
| Chapter 2. JOIN을 이용한 데이터 조합 - (8) 그룹화 : GROUP BY & HAVING 2 (0) | 2023.07.24 |
| Chapter 2. JOIN을 이용한 데이터 조합 - (7) 집계 함수 : SUM, AVG, MIN, MAX (0) | 2023.07.09 |
| Chapter 2. JOIN을 이용한 데이터 조합 - (7) 집계 함수 : COUNT 2 (0) | 2023.06.20 |
| Chapter 2. JOIN을 이용한 데이터 조합 - (7) 집계 함수 : COUNT 1 (0) | 2023.06.15 |



